





首页 > Python基础教程 >
-
python多进程及通信实现异步任务的方法
写在最前面,说实话python多进程这块儿知识对于很少使用python多进程或者没有实际使用过多python进程解决问题的人来说,还是有一定难度的。本人也是很少接触多进程的场景,对于python多进程的使用也是比较陌生的。在接触了一些多进程的业务场景下,对python多进程的使用进行了学习,觉得很有必要进行一个梳理总结。
一、python多进程及通信基本用法
python中多进程及其通信,是比较重要的一块儿内容,作为python程序员,这块儿内容要基本掌握。
1、多进程的基本实现
python多进程的使用一般是调用multiprocessing包中的Process和Pool(进程池),其中Process的用法又有多种,基本函数
p.start()启动一个已经初始化的进程
p.join()让进程运行完了以后,主进程再执行
a、Process重写run方法
MultiOneProcess类继承了multiprocessing的Process类,然后重写它的run方法,实现具体业务逻辑功能;主程序启动10个进程。
from multiprocessing import Process
count = 0
class MultiOneProcess(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self) -> None:
global count
count += 1
print('process name %s is running----count:%d'%(self.name, count))
if __name__ == '__main__':
p_list = []
for i in range(10):
name = 'process_%d'%i
p = MultiOneProcess(name = name)
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('this main process')
b、使用Process和target方法
定义一个进程类继承Process类,同时在super()初始化中传入target函数
from multiprocessing import Process
count = 0
class MultiTwoProcess(Process):
def __init__(self,name):
super().__init__(target=self.do_fun)
self.name = name
def do_fun(self):
global count
count += 1
print('process name %s is running----count:%d' % (name, count))
if __name__ == '__main__':
p_list = []
for i in range(10):
name = 'process_%d'%i
p = MultiTwoProcess(name)
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('this main process')
代码中定义了一个类MultiTwoProcess类,类中定义了do_fun函数,把它作为参数传入到target中。
c、直接使用Process类
传入target函数,同时传入args参数,注意args参数是一个元组,切不能省略最后一个逗号
from multiprocessing import Process
count = 0
def do_fun(name):
global count
count += 1
print('process name %s is running----count:%d' % (name, count))
if __name__ == '__main__':
p_list = []
for i in range(10):
name = 'process_%d'%i
p = Process(target=do_fun,args=(name,))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('this main process')
以上三者运行的结果,是一样的,如下:
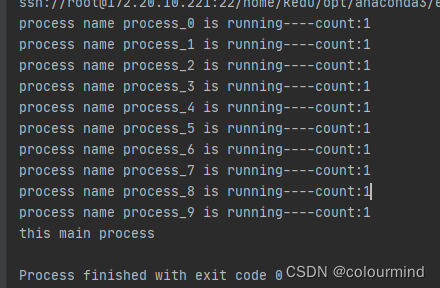
2、多进程的通信
进程之间的通信一般都采用Queue和pipe,区别是:pipe只能在两个进程之间调用,而Queue是可以多个进程间调用的;效率上pipe效率更高,Queue是基于pipe实现的,效率比pipe要低一点。
a、Queue
常用API,
存放数据
queue.put(obj, block=True, timeout=None)
当block=False的时候,如果Queue已经满了,那么就会跑出Queue.Full异常;
当block=True且timeout有正值的时候,Queue已经满了,Queue会阻塞timeout时间,超出时间就会抛出同样的异常
获取数据
queue.get(block=True, timeout=None)
当block=False的时候,如果Queue为空,那么就会跑出Queue.Empty异常;
当block=True且timeout有正值的时候,Queue已经为空,Queue会阻塞timeout时间,超出时间就会抛出同样的异常
以上2个API是阻塞;还有两个非堵塞的API
queue.put(obj, block=False) 和 queue.put_nowait(obj)等效
queue.get(block=False) 和 queue.get_nowait()等效
简单的实现,一个进程发送数据,另外2个进程接收数据,就可以使用queue通信
from multiprocessing import Process, Queue
def send(q):
while True:
q.put('发送一个数据')
def receive1(q):
while True:
s = q.get()
print('receive1:', s)
def receive2(q):
while True:
s = q.get()
print('receive2:', s)
if __name__ == '__main__':
q = Queue()
p1 = Process(target=send,args=(q,))
p2 = Process(target=receive1,args=(q,))
p3 = Process(target=receive2,args=(q,))
p1.start()
p2.start()
p3.start()
p1进程不断的往q中存放数据;p2和p3不停的从q中取数据(有竞争的再取),所以打印结果是无序的
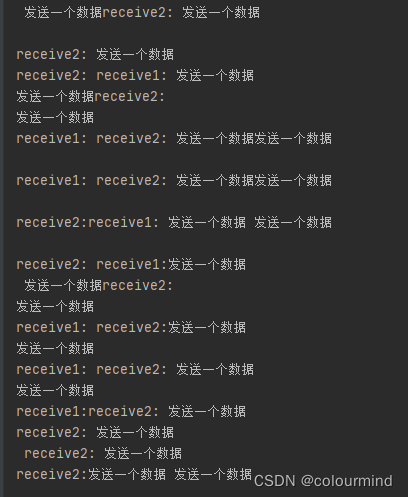
b、Pipe
Pipe(duplex=True)返回2个连通端(p1,p2);当duplex=True时,双向通信,p1发送,p2接收;p2发送,p1接收。
当duplex=True时,单向通信,p1只能发送,p2只能接收。
常用API, pipe.send() pipe.recv()
from multiprocessing import Process, Pipe
def fun2(p):
while True:
s = p.recv()
print('接收一个数据:',s)
def fun1(p):
while True:
print('发送一个数据:pipe')
p.send('pipe')
if __name__ == '__main__':
pi1,pi2 = Pipe(duplex=True)
p1 = Process(target=fun1,args=(pi1,))
p2 = Process(target=fun2,args=(pi2,))
p1.start()
p2.start()
结果如下:

二、python多进程实战
不同的业务场景使用多进程的方式和复杂度也不相同,就我遇见过的一些场景进行演示和说明。
1、使用进程池快速抽取数据
场景描述:有1000个Excel文件的数据需要进行抽取和清洗,要把不符合我们需求的数据过滤掉,保留质量很高的数据;每个Excel都有几十万或者上百万的数据,那么怎么快速的完成这个任务呢?
首先整体上而言,可以把单个Excel的处理并行起来;那么可以使用多进程,其次这个需要返回结果,要保留合格的数据,比较简单的就是采用进程池了,它能够很方便的把进程处理的结果进行返回,并且返回的还是一个生成器;如果还需要更快,那么可以把单个Excel中的每条数据的处理并行起来。代码层面上,采用pool进程池来完成这个任务(本文没有对进程池的使用和API做说明),具体的实现方式采取pool.imap()
if __name__ == '__main__':
#所有Excel的路径
all_paths = glob('../data/original_data/*')
sysInfo_list = ['我通过了好友请求,现在你俩可以开始聊天了', '我通过了你的朋友验证请求,现在我们可以开始聊天了', '已通过你的朋友验证请求,现在可以开始聊天了', '不支持此消息,请在手机上查看',
'微信红包']
interval = 25
if len(all_paths)//interval * interval < len(all_paths):
k = len(all_paths)//interval + 1
else:
k = len(all_paths) // interval
#分段处理,每段25个Excel
for i in range(k):
paths = all_paths[i*interval:(i+1)*interval]
if i*interval >= 100 and i*interval < 200:
params = []
for path in tqdm(paths):
params.append((path, sysInfo_list))
#多进程处理——进程池、以及进度显示
with Pool(20) as p:
res = list(tqdm(p.imap(extract_data, params), total=len(params), desc='extract_data'))
all_df = []
for dfs in res:
if len(dfs) > 0:
all_df.extend(dfs)
df = pd.concat(all_df, axis=0)
save_path = '../data/weikong_clean_data_'+str(i*interval)+'_'+str(i*interval+len(paths)-1)+'.xlsx'
writer = pd.ExcelWriter(save_path)
df.to_excel(writer, index=False)
writer.save()
writer.close()
2、多进程及通信完成数据清洗和保存
场景描述:从Excel中读取数据,数据格式是整通整通的对话,每通对话有一定的轮数;保存数据到2个txt中,一个是顺序保留,一个是倒序保留;整体对话顺序不变,每通对话内部顺序倒序。
正序:
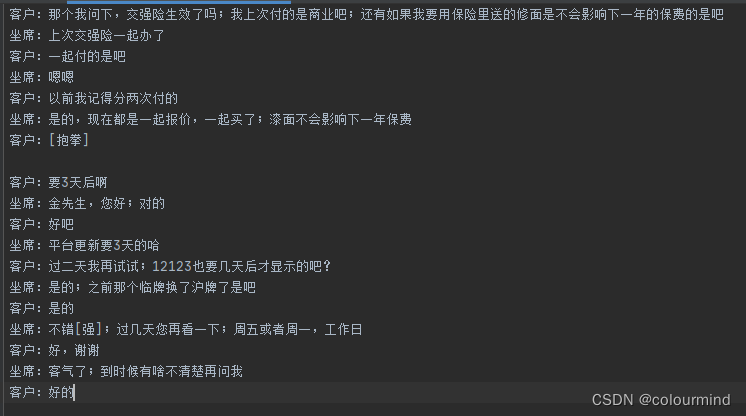
倒序:
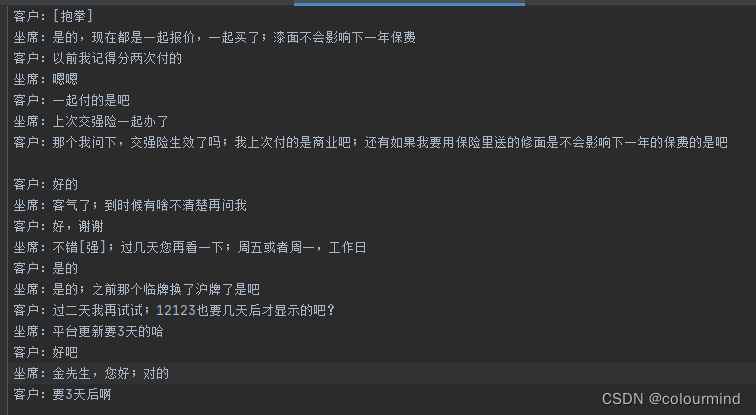
要想实现这样的任务,粗暴的做法是,用两个list,一个保留正序的,一个保留倒序的,然后分别对这两个list进行文件写入操作。但是如果数据量很多在内存有限的时候,只能满足不了两个list的情况下怎么实现呢?
我的实现方式就是开启两个进程,一个进程保留一个正序list,写入文件的同时对每个元素(每通)对话进行倒序,然后把倒序后的数据通过Queue或者Pipe传入到另外一个进程,让另外的进程进行写文件操作。
def save_mmi_train_data(queue):
with open('../data/finetune_mmi_data/train.txt','w',encoding='utf-8') as f:
while True:
save_list = queue.get()
if len(save_list) == 0:
break
for line in save_list:
f.write(line)
def save_mmi_val_data(queue):
with open('../data/finetune_mmi_data/val.txt','w',encoding='utf-8') as f:
while True:
save_list = queue.get()
if len(save_list) == 0:
break
for line in save_list:
f.write(line)
def get_funtine_data(paths):
all_groups = []
for path in tqdm(paths,desc='load data from excle'):
df = pd.read_excel(path)
df.dropna(inplace=True)
df.drop_duplicates(inplace=True, keep='first')
groups = list(df.groupby(by=['坐席id', '客户微信id']))
all_groups.extend(groups)
print('len(all_groups)',len(all_groups))
train, val = train_test_split(all_groups,test_size=10000/len(all_groups),random_state=1)
print('len(train)', len(train))
print('len(val)', len(val))
train_std_path = '../data/finetune_std_data/train.txt'
val_std_path = '../data/finetune_std_data/val.txt'
train_mmi_queue = Queue()
save_funtine_data(train, train_std_path,train_mmi_queue,save_mmi_train_data)
val_mmi_queue = Queue()
save_funtine_data(val, val_std_path, val_mmi_queue, save_mmi_val_data)
def save_funtine_data(groups,save_std_path,queue,fun):
p = Process(target=fun,args=(queue,))
p.start()
with open(save_std_path,'w', encoding='utf-8') as f:
for group in tqdm(groups, desc='find and save funtine dialogue datas'):
new_df = group[1]
df_roles = new_df['是否客服'].values.tolist()
df_contents = new_df['消息内容'].values.tolist()
roles = []
contents = []
for role,content in zip(df_roles,df_contents):
content = content.replace('\n', '')
content = emoji.replace_emoji(content, '')
if len(content) > 0 and content != "":
roles.append(role)
contents.append(content)
save_list = []
save_str = ""
for index, role in enumerate(roles):
content = contents[index].replace('\n','')
content = emoji.replace_emoji(content, '')
if content[-1] not in punctuations:
content += ';'
if index == 0:
if role == "是":
save_str += "坐席:"+content
else:
save_str += "客户:"+content
else:
if role != roles[index-1]:
f.write(save_str[0:-1]+'\n')
save_list.append(save_str[0:-1]+'\n')
if role == "是":
save_str = "坐席:" + content
else:
save_str = "客户:" + content
else:
save_str += content
if len(save_str) > 1:
save_list.append(save_str[0:-1] + '\n')
f.write(save_str[0:-1]+'\n')
f.write('\n')
# 切片反转
save_list = save_list[::-1]
save_list.append('\n')
if len(save_list) > 0:
queue.put(save_list)
#注意传入一个空值,让倒序进程结束
queue.put([])
p.join()
要注意的是,倒序进程中使用while True 无限循环,需要传入一个空值,能够让它在正序进程结束的同时知道数据写完了,跳出循环。以上代码比较简单就不一一说明了。
3、多进程及通信实现异步任务需求
场景描述:假定一个模型推理系统,网络模块负责接受请求传输的数据,把数据传输给数据处理模块;数据处理模块负责处理数据(比如说语音流或者视频流等,这些数据处理对CPU的消耗很大),处理完后把数据传输给模型推理模块;模型推理模块负责对数据进行推理并把结果返回给网络模块。要求就是网络模块、数据处理模块和模型推理模块是独立的,可以并行的完成自己的任务,3个模块是异步的,其实可以把这个系统简化的使用多进程来实现。
每个模块可以用一个进程来表示,内部的逻辑可以开启子进程来实现,然后模块直接的数据传输就可以使用多进程的通信来实现,同时也创建一个全局的Queue变量,让每个模块的进程按需使用。
画了一个简单的结构和流程图,如下:
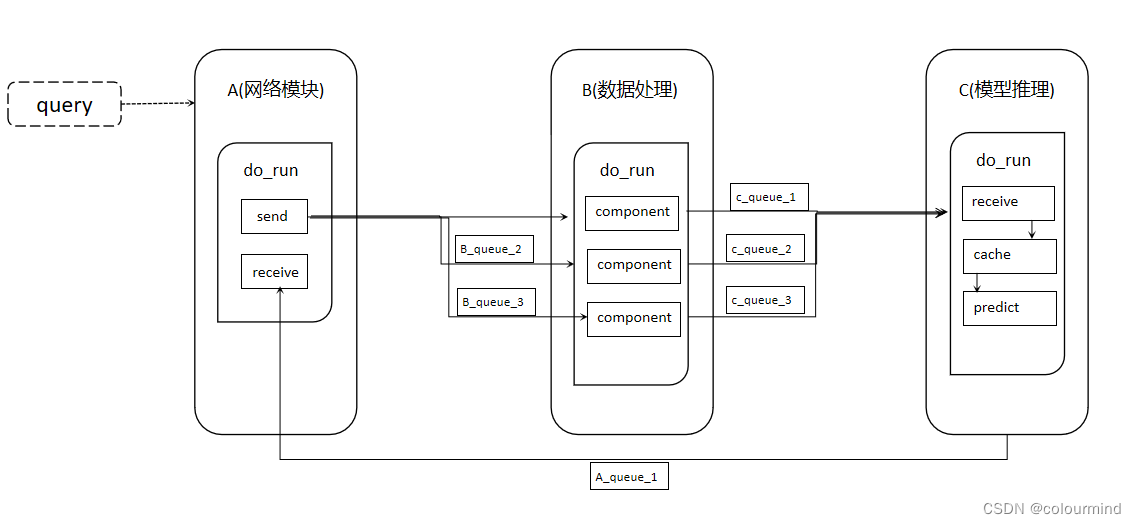
注意的是模块之间的数据传输,使用queue传输的时候,数据量越小,效率越高,所以可以在网络模块这端提前把数据进行处理。
函数入口文件
import a
import b
import c
from whole_queue import WholeQueue
import os
if __name__ == '__main__':
print("main process:",os.getpid())
whole_queue = WholeQueue()
b_pool_size = 2
c_pool_size = 6
Module_list = [
a.A(whole_queue,b_pool_size),
b.B(whole_queue,b_pool_size,c_pool_size),
c.C(whole_queue,c_pool_size)
]
for p in Module_list:
p.start()
公共队列类
class WholeQueue():
def __init__(self):
self.queues = dict()
def register(self,queuename,queue):
self.queues[queuename] = queue
各个子模块类
a
from multiprocessing import Process,Queue
import time
import random
import os
class A(Process):
def __init__(self,whole_queue,b_pool_size):
super().__init__(target=self.do_run)
self.whole_queue = whole_queue
self.b_pool_size = b_pool_size
self.queue_list = []
queue = Queue()
self.whole_queue.register('A', queue)
self.queue_list.append(queue)
self.count = 0
def do_run(self):
print("A.do_run process:", os.getpid())
a_send_pro = Process(target = self.send)
a_send_pro.start()
a_receive_pro = Process(target = self.receive)
a_receive_pro.start()
def send(self):
print("A.send process:", os.getpid())
while True:
time.sleep(0.001)
self.whole_queue.queues['B_%d'%(self.count%self.b_pool_size)].put_nowait(self.count)
self.count += 1
def receive(self):
print("A.receive process:", os.getpid())
while True:
rece = self.whole_queue.queues['A'].get()
print(rece)
b
from multiprocessing import Process,Queue
import time
import random
import os
class B(Process):
def __init__(self,whole_queue,b_pool_size,c_pool_size):
super().__init__(target=self.do_run)
self.whole_queue = whole_queue
self.b_pool_size = b_pool_size
self.c_pool_size = c_pool_size
self.queue_list = []
for i in range(self.b_pool_size):
queue = Queue()
self.whole_queue.register('B_%d'% i , queue)
self.queue_list.append(queue)
self.count = 0
def do_run(self):
print("B.do_run process:", os.getpid())
for i in range(self.b_pool_size):
p = Process(target=self.component,args=(self.queue_list[i],))
p.start()
def component(self, queue):
print("B.component process:", os.getpid())
while True:
time.sleep(0.01)
info = queue.get()
componext_info = 'component_' + str(info)
self.whole_queue.queues['C_%d'%(info%self.c_pool_size)].put(componext_info)
c
from multiprocessing import Process,Queue
from model import Model
import time
import random
import os
class C(Process):
def __init__(self,whole_queue,c_pool_size):
super().__init__(target=self.do_run)
self.whole_queue = whole_queue
self.c_pool_size = c_pool_size
self.queue_list = []
for i in range(self.c_pool_size):
queue = Queue()
self.whole_queue.register('C_%d'% i , queue)
self.queue_list.append(queue)
# self.cache_queue = None
# self.result_queue = None
# self.infer_queue = None
def do_run(self):
cache_queue = Queue()
result_queue = Queue()
infer_queue = Queue()
print("C.do_run process:", os.getpid())
for i in range(self.c_pool_size):
p = Process(target=self.receive,args=(self.queue_list[i], cache_queue,))
p.start()
cache_p = Process(target=self.cache,args=(cache_queue, infer_queue,))
cache_p.start()
predict_p = Process(target=self.predict,args=(infer_queue, result_queue))
predict_p.start()
while True:
res = result_queue.get()
for ele in res:
self.whole_queue.queues['A'].put(ele)
def receive(self, queue,cache_queue):
print("C.receive process:", os.getpid())
while True:
info = queue.get()
receive_info = 'receive_' + info
cache_queue.put(receive_info)
def cache(self,cache_queue, infer_queue):
timeLast = time.time()
print("C.cache process:", os.getpid())
caches = []
while True:
data = cache_queue.get()
caches.append(data)
if len(caches) > 128 or time.time() - timeLast > 1:
timeLast = time.time()
infer_queue.put(caches)
caches = []
def predict(self,infer_queue, result_queue):
print("C.predict process:", os.getpid())
# 模型必须在这里初始化
model = Model()
while True:
data = infer_queue.get()
result = model(data)
result = [ 'modelpredict_' + ele for ele in result]
time.sleep(random.uniform(0.1,0.5))
result_queue.put(result)
代码比较好理解,需要注意的是子进程在使用变量的时候,例如初始后的模型,应该要每一个子进程独立的进行初始化,不然会报错,就是C类中模型初始化不能在init中初始后,然后传入到每个子进程中去——而应该在每个子进程中初始化。
到此这篇关于python多进程及通信实现异步任务需求的文章就介绍到这了,更多相关python异步任务内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持
原文链接:https://blog.csdn.net/HUSTHY/article/details/123273336




